How many arrays can I RMA process?
Written by Ben Bolstad
|
Special Note
This page was originally compiled in Mid-2003 (except this section) and is now somewhat outdated. In the intervening period of time 64 bit processors have become more common and dataset limits have increased. What is called just.rma2() below became just.rma(). In addition RMAExpress as of version 0.4 can process extremely large datasets.
|
Simulation Outline
Using this script we simulate the process of reading in and RMA processing an arbitrary number of arrays. The test.cel file was a HGU_95Av2 array. We compared
- rma()
- expresso()
- just.rma()
- just.rma2()
To fairly compare we also include times for reading data in using ReadAffy() in the times for rma() and expresso(). The read.affybatch2() function was used in place of read.affybatch(). This function is a little faster and has a lower memory overhead.
|
Results
The times shown here are real world ties as reported by system.time(). The figures in parentheses is the time not including ReadAffy() time. A red box indicates we were not able to complete because R could not allocate necessary memory or the operating system killed the process (again it could not allocate the required memory).
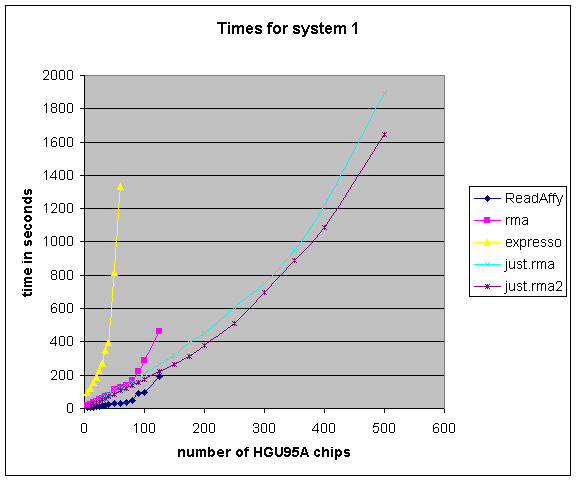
System 1 represents a higher end linux machine. The raw results for system 1.
| Results using system 1 (specifications below) |
| # arrays | ReadAffy() | rma() | expresso() | just.rma | just.rma2() |
| 5 | 3.51 | 20.05 (16.54) | 98.35 (94.84) | 11.48 | 11.86 |
| 10 | 6.31 | 25.73 (19.42) | 120.94 (114.63) | 21.01 | 19.9 |
| 15 | 8.91 | 34.35 (25.44) | 158.14 (149.23) | 30.19 | 27.94 |
| 20 | 11.35 | 43 (31.65) | 187.48 (176.13) | 39.57 | 36.09 |
| 25 | 13.91 | 52 (38.09) | 231.07 (217.16) | 48.46 | 43.97 |
| 30 | 16.51 | 60.43 (43.92) | 271.19 (254.68) | 61.97 | 52.58 |
| 35 | 19.02 | 69.2 (50.18) | 351.11 (332.09) | 71.69 | 60.55 |
| 40 | 21.6 | 78.08 (56.48) | 398.56 (376.96) | 85.79 | 69.69 |
| 50 | 31.79 | 112.34 (80.55) | 817.12 (785.33) | 114.77 | 85.52 |
| 60 | 32.91 | 123.27 (90.36) | 1330.58 (1277.24) | 120.42 | 107.45 |
| 70 | 36.96 | 138.97 (102.01) | | 137.6 | 122.69 |
| 80 | 50.67 | 166.62 (115.95) | | 157.51 | 139.01 |
| 90 | 89.82 | 224.53 (134.71) | | 175.64 | 154.8 |
| 100 | 99.06 | 285.96 (186.9) | | 207.25 | 173.85 |
| 125 | 193.77 | 460.14 (266.37) | | 261.96 | 219.77 |
| 150 | | | | 320.72 | 264.3 |
| 175 | | | | 395.06 | 309.39 |
| 200 | | | | 447.93 | 379.73 |
| 250 | | | | 603.84 | 507.97 |
| 300 | | | | 750.93 | 699.6 |
| 350 | | | | 948.7 | 889.16 |
| 400 | | | | 1218.95 | 1084.71 |
| 500 | | | | 1891.04 | 1648.08 |
System 2 represents a more moderate linux machine. The raw results for system 2.
| Results using system 2 (specifications below) |
| # arrays | ReadAffy() | rma() | expresso() | just.rma | just.rma2() |
| 5 | 5.94 | 33.04 (27.1) | 160.28 (154.34) | 19.88 | 20.54 |
| 10 | 10.71 | 44 (33.29) | 211.48 (200.77) | 36.85 | 34.89 |
| 15 | 15.21 | 59.2 (43.99) | 404.67 (389.46) | 53.79 | 50.14 |
| 20 | 19.77 | 75.62 (55.85) | 647.09 (627.32) | 72.61 | 64.96 |
| 25 | 24.11 | 90.99 (66.88) | 1128.41 (1104.3) | 105.72 | 80.52 |
| 30 | 27.89 | 112.33 (84.44) | 1744.07 (1678.78) | 106.8 | 97.64 |
| 35 | 53 | 167.47 (114.47) | 2682.55 (2574.9) | 123.8 | 113.61 |
| 40 | 38.86 | 143.48 (104.62) | | 139.56 | 127.03 |
| 50 | 127.41 | 298.13 (170.72) | | 174.81 | 156.62 |
| 60 | 308.58 | 672.27 (363.69) | | 260.84 | 189.01 |
| 70 | 489.28 | 1247.48 (758.2) | | 278.75 | 223.81 |
| 80 | 606.88 | 1738.64 (1131.76) | | 359.88 | 255.99 |
| 90 | 871.76 | 2256.15 (1384.39) | | 393.73 | 287.93 |
| 100 | | | | 435.42 | 313.9 |
| 125 | | | | 649.41 | 470.33 |
| 150 | | | | 812.56 | 706.42 |
| 175 | | | | 976.76 | 845.67 |
| 200 | | | | 1435.81 | 957.63 |
| 250 | | | | | 2578.11 |
| 300 | | | | | 4526.76 |
| 350 | | | | | 11640.77 |
| 400 | | | | | |
System 3 represents a windows machine. The raw results for system 3.
| Results using system 3 (specifications below) |
| # arrays | ReadAffy() | rma() | expresso() | just.rma | just.rma2() |
| 5 | 5.39 | 23.56 (18.17) | 117.72 (112.33) | 15.79 | 15.19 |
| 10 | 9.99 | 32.55 (22.56) | 146.32 (136.33) | 28.91 | 26.24 |
| 15 | 14.32 | 44.3 (29.98) | 217.4 (203.08) | 51.81 | 38.09 |
| 20 | 41.12 | 99.78 (58.66) | 343.6 302.48 | 82.12 | 49.97 |
| 25 | 23.02 | 69.92 (46.9) | 370.41 347.39 | 88.83 | 61.68 |
| 30 | 27.38 | 83.95 (56.57) | 583.15 555.77 | 168.94 | 73.13 |
| 35 | 31.78 | 94.08 (62.3) | | 96.71 | 85.57 |
| 40 | 40.25 | 110.94 70.69 | | 109.75 | 95.42 |
| 50 | 45.15 | 130.58 85.43 | | 137.22 | 118.68 |
| 60 | 53.93 | 172.54 118.61 | | 166.36 | 141.49 |
| 70 | 64.52 | 207.06 142.54 | | 218.14 | 168.17 |
| 80 | 99.74 | 384.01 284.27 | | 253.03 | 195.12 |
| 90 | 132.14 | 690.56 558.42 | | 333.43 | 250.19 |
| 100 | 275.79 | 724.78 448.99 | | 441.18 | 303.77 |
| 125 | | | | 528.84 | 601.93 |
| 150 | | | | 506.53 | 403.85 |
| 175 | | | | 594.5 | 537.17 |
| 200 | | | | 738.45 | 1055.84 |
Plots of running times for system 1, system 2 and system 3.
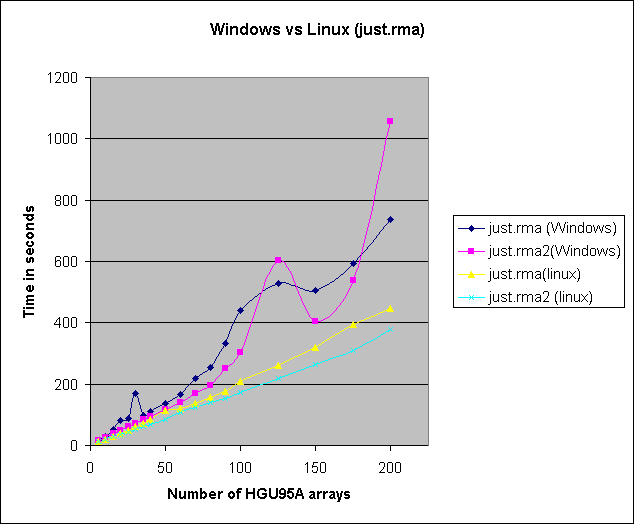
Comparing windows to linux on the same hardware: rma() and justrma()
TO COME ...... simulation with HGU133A chip (more probes and probesets),
|
Discussion
Currently we would rank (in terms of number of chips that you will be able to process) the methods in the order: just.rma2, just.rma, rma, expresso.
Their is some upwards bias in the times due to the way the simulation was run. Because of the way the operating system moves memory pages in and out of swap if a large amount of memory was allocated previously, the following routines might also suffer. Generally after about 100 arrays each iteration of the simulation was carried out in a fresh R session to reduce this problem. (The bias was due to wanting to avoid babysitting the machine too much). In places where this bias was heavily apparent the simulation was rerun for the individual method to get a more accurate estimate of time.
It is important to note the processes have a 3 GB memory limit on 32bit x86 linux machines. On windows machiens this is typically 2GB.
read.affybatch2() suffers when the affybatch object is instantiated. The instantiation process seems to use much more memory than necessary. Both rma() and expresso() cannot be carried out without a affybatch object. This is why times for rma() finish when the affybatch object can no longer be created.
On the windows machine the memory limit was 1.6GB (this is as far as I could raise it and have a stable R session). See the R on Windows FAQ on this matter. The results for just.rma2 were affected by it running in sequence after just.rma (see the CPU time to see that just.rma2 is faster).
|
Test machine specifications
| System 1 specifications |
| Component | Description |
| Processor | AMD Athlon XP 2500+ (Barton) |
| RAM | 1 GB |
| Swap | 6 GB |
| Operating System | Red Hat Linux 9 |
| Kernel | 2.4.21-rc7-ac1 |
| R | 1.7.1 |
| affy | 1.3.6 |
| System 2 specifications |
| Component | Description |
| Processor | Intel Pentium 4M 1.7 GHz |
| RAM | 640 MB |
| Swap | 1 GB |
| Operating System | Red Hat Linux 9 |
| Kernel | 2.4.20-18.9 |
| R | 1.7.1 |
| affy | 1.3.6 |
| System 3 specifications |
| Component | Description |
| Processor | AMD Athlon XP 2500+ (Barton) |
| RAM | 1 GB |
| Swap | 6 GB |
| Operating System | Windows XP pro |
| R | 1.7.1 |
| affy | 1.3.6 |
|
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}