Timing simulations for BufferedMatrixMethods 1.3.5 (Simulation 1)
Background
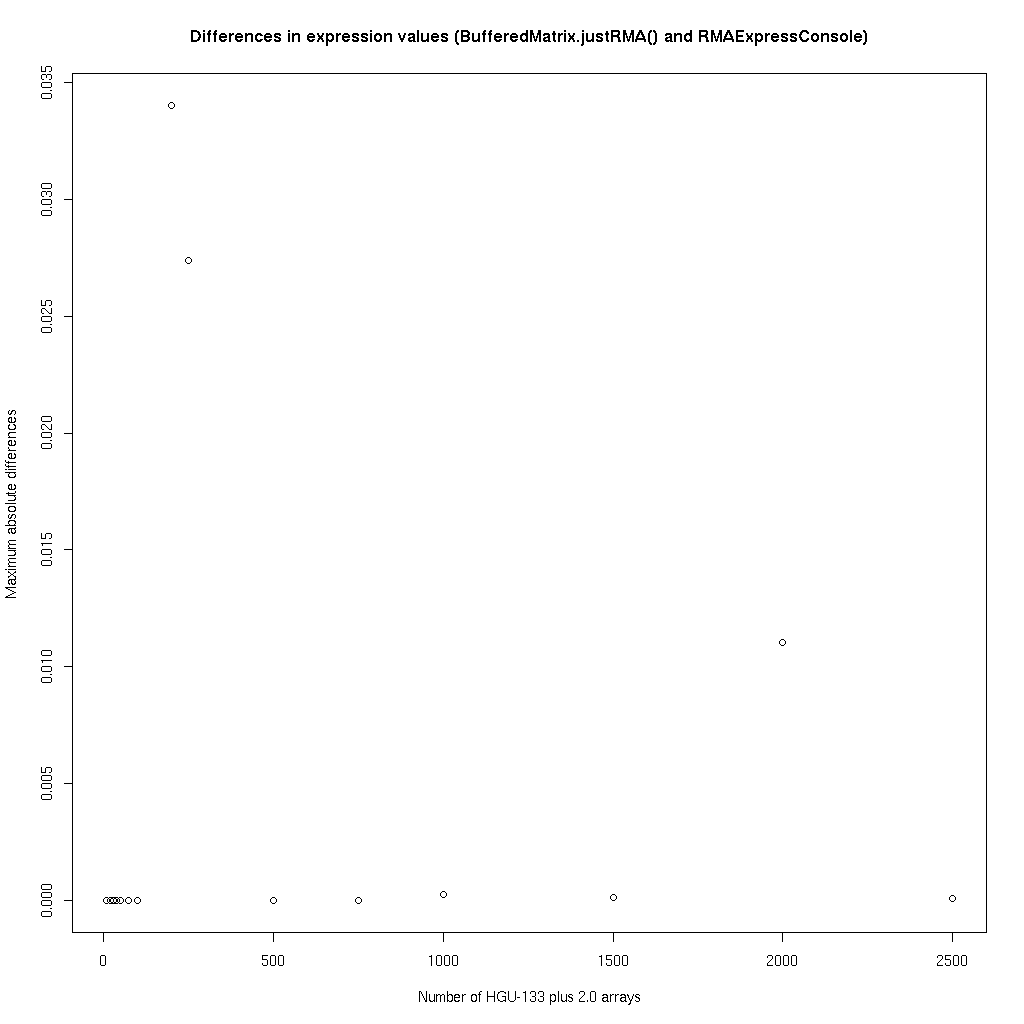
The goal here was to investigate the speed of BufferedMatrix.justRMA() as a function of the number of arrays processed between 10 and 2500 hgu-133 Plus 2.0 arrays and compare that to the performance of RMAExpressConsole. To make a fair comparison, both were used to read in the same set of arrays, RMA process them and then write the output to text files. pick_datasets.R Code used to select the subset of arrays used in each analysis.RMAExpressTiming.sh Script for running and timing RMAExpressConsole
R_Timing.sh Script for running and timing BufferedMatrix.justRMA()
output_10.settings Settings file for RMAExpressConsole (using 10 arrays as example)
Process10.R R script that used BufferedMatrix.justRMA() (using 10 arrays as example)
compareoutput.R Look at all the output and compare it.
Results
RMAExpressConsole_log.txt R_log.txt RMAExpressTimes.txt R_Times.txt