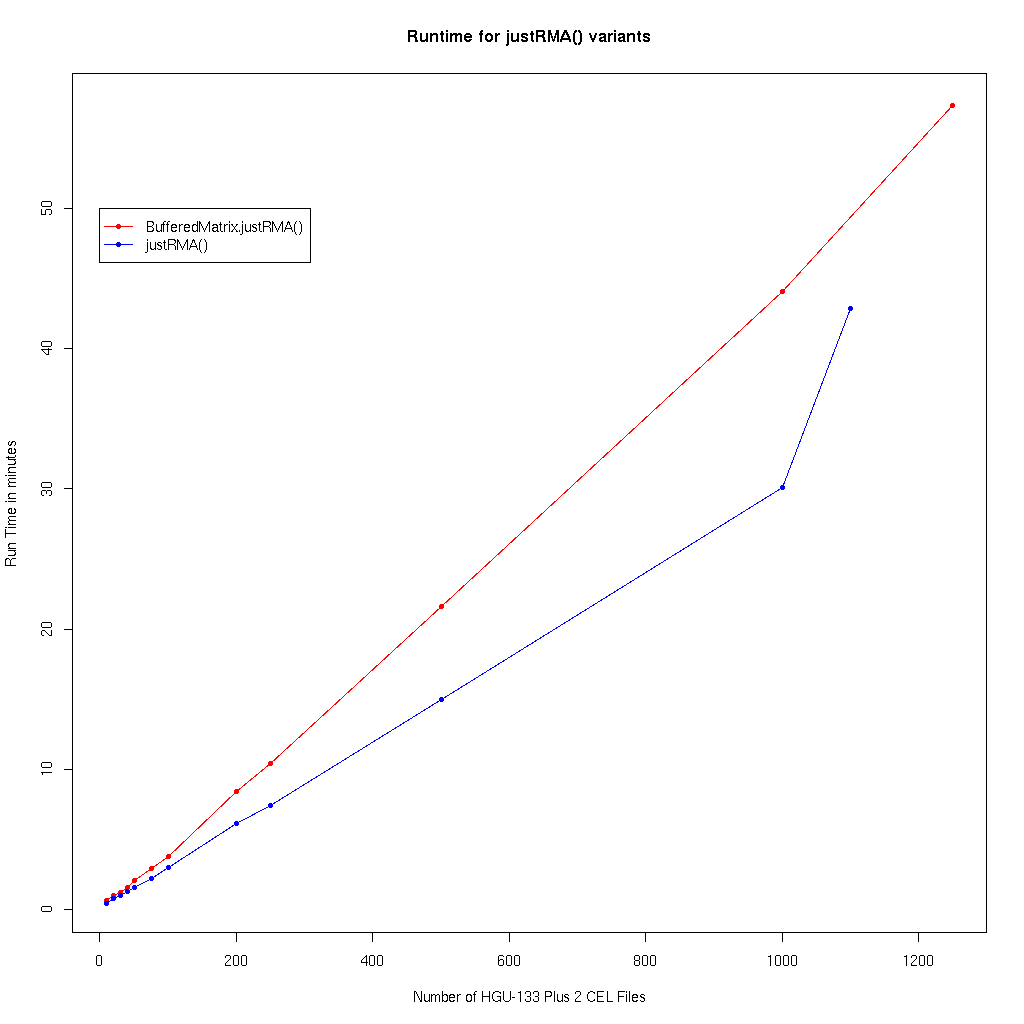
Timing simulations for BufferedMatrixMethods 1.3.2 (Simulation 2)
Background
The goal here was to investigate the speed of BufferedMatrix.justRMA() as a function of the number of arrays processed between 10 and 1250 HGU-133 Plue 2.0 arrays and compare it to performace of justRMA() Source code (note takes very long time to run)Results